| Pixelated Noise is a software consultancy and we're always looking for interesting projects to help out with. If you have unmet software development needs, we would be happy to hear from you. |
This is the blog version of a talk I gave on the 2017-12-13 at the Athens Clojure Meetup, which was kindly hosted by Skroutz. The video of the talk is available (the talk was given in Greek, but there are English subtitles). This blog entry is not an exact transcript of the talk, I've added links and more information where appropriate (plus the "bonus" sections that were not in the talk). Since the talk was given a while ago, some information will be outdated.
There are essentially two parts to this article: the "what it is" part which introduces the basic concepts and mechanisms of spec, and also provides some information so that non-Clojurians can see how spec fits into the larger picture and the "what you can do with it" part which explores some more interesting use cases that go beyond basic usage.
Clojure is a dynamic language that doesn't enforce the types of parameters or the return values of functions. This has been a characteristic of the language that has drawn criticism both internally and from other language communities and has possibly been a factor impeding adoption in the past.
Spec in a way is the response to that, but it's a response that maybe the community didn't expect because it does not take the traditional approach of checking types statically. At a very fundamental level spec is a declarative language that describes data, their type, their shape. Spec follows the general philosophy of Clojure in that all of its functionality is available at runtime, you can use it, introspect it, generate it – there is no extra step before execution when the compiler checks your whole codebase for errors.
Spec is still alpha, so the namespace in the require contains .alpha to indicate
that. The following spec defines a username "entity" and says that it has to be
a string:
(require '[clojure.spec.alpha :as s]) (s/def ::username string?)
string? is a simple function that exists in Clojure core, it's a
predicate function that you pass a string to and it returns true or
false, depending on whether the passed value is a string or not.
Once you've defined a spec the simplest usage of it is to ask whether
something is valid, by calling valid?, and passing the name of the
spec and then a value:
(println (s/valid? ::username "foo"))
true
Many cases are covered by built-in predicates, but that doesn't mean we can't use our own. If we need a spec that checks that a number is above 5, we can simply write an anonymous function like this one, and then use it normally as it if was a spec itself:
(s/valid? #(> % 5) 10)
true
And it works as expected with different inputs:
(s/valid? #(> % 5) 3)
false
So, we write a spec and it can validate our data. Let's draw this as a diagram: the thing on the left that looks like a blueprint is a spec and the curly braces on the right represents Clojure data (because very often data in Clojure are maps and maps are written with curly braces). Read the weird arrow in the middle as "validates":
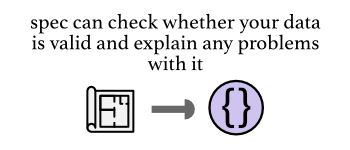
It's not much of a diagram, but I'm trying to establish the visual language for the rest of this article.
Specs can also be applied to collections by composing and nesting
more basic specs together. Here we define an entity called usernames
made up of a collection of username:
(require '[clojure.spec.alpha :as s]) (s/def ::username string?) (s/def ::usernames (s/coll-of ::username)) (println (s/valid? ::usernames ["foo" "bar" "baz"]))
true
You would normally not define this as a separate entity for something that
simple, as s/coll-of can be used ad-hoc in your program.
Maps are a bit more interesting. Other technologies such as plumatic schema (which at some point was the de facto way to validate data in Clojure), ask you to define both the keys that have to be present in a map and the data types of the values that correspond to the keys. The resulting definition looks a bit like a rigidly-defined class that you usually see in object-oriented languages. Spec very deliberately moves away from this mentality: the maps are not like objects, they are not fixed and do not necessarily exist in that one shape. Instead, maps simply happen to be aggregations of some named values.
This design decision is embodied in two ways:
s/keys which does not define the types of
the values of the map, we only define which existing entities make
up the map.
In this case we have defined some single-value specs like username,
password, last-login and comment, and they are aggregated together
in a map defined by the ::user spec.
(ns my-project.users (:require [clojure.spec.alpha :as s])) (s/def ::username string?) (s/def ::password string?) (s/def ::last-login number?) (s/def ::comment string?) (s/def ::user (s/keys :req [::username ::password] :opt [::comment ::last-login])) (println ::username) (println (s/valid? ::user {::username "rich" ::password "zegure" ::comment "this is a user" ::last-login 11000}))
:my-project.users/username ;;this is what fully-qualified keywords look like true
Spec also encourages the use of qualified keywords: Until recently
in Clojure people would use keywords with a single colon but the two
colons (::) mean that keywords belong to this namespace, in this
case my-project.users. This is another deliberate choice, which is
about creating strong names (or "fully-qualified"), that belong to a
particular namespace, so that we can mix namespaces within the same
map. This means that we can have a map that comes from outside our
system and has its own namespace, and then we add more keys to this
map that belong to our own company's namespace without having to
worry about name clashes. This also helps with data provenance,
because you know that the :subsystem-a/id field is not simply an ID
– it's an ID that was assigned by subsystem-a.
The other interesting thing about specs for maps is that they are
open. For example, if we use the same exact map as before, with the
same fields and an additional field called ::age, it's still a valid
::user:
(ns my-project.users (:require [clojure.spec.alpha :as s])) (s/def ::username string?) (s/def ::password string?) (s/def ::last-login number?) (s/def ::comment string?) (s/def ::user (s/keys :req [::username ::password] :opt [::comment ::last-login])) (println (s/valid? ::user {::username "rich" ::password "zegure" ::comment "this is a user" ::last-login 11000 ::age 26}))
true
This happens because spec does not mind if you've defined four keys, if it sees a fifth key the map does not become invalid. The reason for this is that when we have a system that accumulates information this accumulation should not break the system, the code that consumes the map should simply ignore the keys it doesn't know about. If you're making a system and you're accumulating extra options, parameters, whatever it is – your code should be able to continue to run without having to change a lot of code locations, like you would have to do in an object oriented language or Haskell.
This accumulation has also been described by the term "accretion" and has been discussed in the excellent Spec-ulation Keynote talk by Rich Hickey.
On the other hand, a lot of people who use spec to validate things coming from outside their system need to be more strict with maps, and they have complained about the openness of maps. We'll talk about proposed solutions to this issue later.
Another usage of specs, beyond validation, is "explain" which essentially can produce errors that tell you what's wrong with your data. In this case we'll try to create an error by creating a user that's invalid because it doesn't have a password – a required key:
(ns my-project.users (:require [clojure.spec.alpha :as s])) (s/def ::username string?) (s/def ::password string?) (s/def ::last-login number?) (s/def ::comment string?) (s/def ::user (s/keys :req [::username ::password] :opt [::comment ::last-login])) (s/explain ::user {::username "rich" ::comment "this is a user"})
We get an ok-ish error that tells us that for the particular map we
passed, the ::user spec fails because it doesn't contain ::password.
val: #:my-project.users{:username "rich", :comment "this is a user"} fails spec: :my-project.users/user predicate: (contains? % :my-project.users/password)
A powerful mechanism in spec is sequences. We've already seen s/coll-of which
contains a uniform type of values (a collection of numbers for example) but
sequences are a bit more like regular expressions for data. In this case we
have a sequence with two things, which describe an ingredient for a recipe:
the first thing is a number for the quantity and the second thing is a unit
encoded as a keyword.
(require '[clojure.spec.alpha :as s]) (s/def ::ingredient (s/cat :quantity number? :unit keyword?))
With s/cat we always have to give a name to each position. s/cat
allows to both validate the shape of the value passed, but it also
enables the "conform" operation, which is somehow similar to parsing
or destructuring. If we pass a vector of two elements – a number and
a keyword – we get back a map with the defined names:
(prn (s/conform ::ingredient [2 :teaspoon]))
{:quantity 2, :unit :teaspoon}
By using some of the other operators which are reminiscent of regular
expressions, this technique can become quite powerful. As an example, we'll
try and create a very simple grammar that can parse a very limited subset of
the Clojure syntax. Specifically, we will attempt to parse defn, which is the
macto used to define functions. The s-expression includes defn as a symbol,
then a symbol that defines the name of the function, then an optional
docstring (a string), a vector of the arguments, and finally the function
body.
Let's express this as a cat spec:
(require '[clojure.spec.alpha :as s] '[clojure.pprint :as pp]) (s/def ::function (s/cat :defn #{'defn} :name symbol? :doc (s/? string?) :args vector? :body (s/+ list?)))
So this is how what our spec looks like: there is a defn part, which is always
the symbol defn. We use a set as the predicate, so a value passes if it's
contained in the set. Then we have :name which is a symbol. Next we have s/?
for the docstring which means that there can be zero or one strings in that
position. After that we have the argument which is a vector (with undefined
contents to keep things simple), and finally a list to hold the function's
body.
We can try our spec on some data that looks like a valid Clojure function (remember, we're in a Lisp, so code is data is code!):
(def function-code1 '(defn my-function "this is a test function" [x y] (+ x y))) (pp/pprint (s/conform ::function function-code1))
{:defn defn,
:name my-function,
:doc "this is a test function",
:args [x y],
:body [(+ x y)]}
The different parts are properly identified. Now let's try conforming the same function but without the docstring:
(def function-code2 '(defn my-function [x y] (+ x y))) (pp/pprint (s/conform ::function function-code2))
{:defn defn, :name my-function, :args [x y], :body [(+ x y)]}
Again, the different parts are properly identified.
This opens up a lot of possibilities for DSLs, for validating macros etc and
it's generally a very powerful technique. This kind of code to handle optional
values in the middle of a sequence is tricky to write in a functional way, so
conform helps a lot.
Spec is a declarative skeleton made of up s/keys, s/cat, s/+, s/* etc and
right at the bottom there are predicates. Since this is a declarative
description of the data shape, we don't define how this information is to be
used. We've already seen validation but specs have enough encoded knowledge about
the shape of the data to be able to construct new instances of the data that
fits the described shape.
So given a spec, we can make a generator out of it and then sample that generator:
(ns my-project.users (:require [clojure.spec.alpha :as s] [clojure.spec.gen.alpha :as gen] [net.cgrand.packed-printer :as ppp])) (s/def ::username string?) (s/def ::password string?) (s/def ::last-login number?) (s/def ::comment string?) (s/def ::user (s/keys :req [::username ::password] :opt [::comment ::last-login])) (ppp/pprint (gen/sample (s/gen ::user) 5))
({:my-project.users/username "", :my-project.users/password "",
:my-project.users/comment "", :my-project.users/last-login 0}
{:my-project.users/username "L", :my-project.users/password "G",
:my-project.users/last-login 3.0, :my-project.users/comment "a"}
{:my-project.users/username "Q", :my-project.users/password "",
:my-project.users/comment "qO", :my-project.users/last-login 0}
{:my-project.users/username "", :my-project.users/password "", :my-project.users/last-login 0}
{:my-project.users/username "M6", :my-project.users/password "nyX0"})
If you run this code a few times, you'll get different user maps every time.
Having such generators is useful in many cases. A very simple use case would be to fill a database with valid data of any volume you like and use it to do performance testing.
Another use case that I've encountered in practice is that in some cases you'd like to write a unit test but you don't want to want to write the whole fixture by hand. We had a spec that described a big configuration structure, and we used it to generate one sample of the whole configuration, and then we overwrote specific parts of the configuration before using it as a fixture in the unit test.
In some cases it becomes necessary to provide a spec and override some of the default generators with your own custom ones, which is a technique covered in this highly recommended talk by Gary Fredericks.
The big "win" for spec is of course validating functions using property testing (also known as generative testing). Property testing is a bit like graduating from unit testing where all inputs and expected outputs are written by hand and recognising that with unit testing we often stay on the "happy path" of functions and test for simple cases only. Property testing forces us to stray from the happy path by demanding more general thinking and puts us in a position where we have to think more about the properties that have to hold for our code to be correct.
In order to test a function with spec, you have to make three different specs for the three different aspects of the function.
The first one is the :args spec which is an s/cat, and describes the arguments
of the function. That can include specs that describe the relationship between
arguments. For example argument 1 and argument 2 may have to be consecutive
numbers or if one parameter is present, the other one has to be there as well,
so both are present or neither of them (for optional parameters that have to
co-exist).
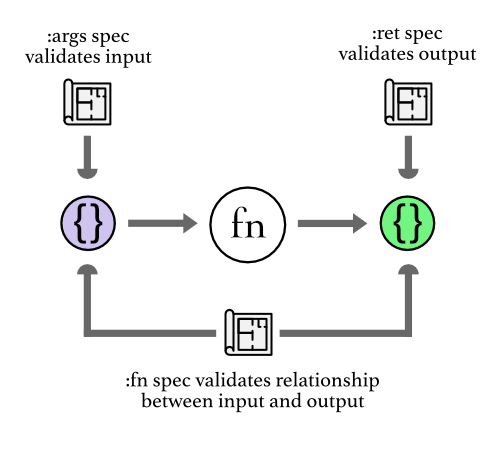
You then make a spec that validates the result value of the function, called
:ret spec. And finally you have :fn spec which is about the relationship
between the arguments and the result of the function, if such a relationship
exists. :args, :ret and :fn are all optional – you don't have to define all
three.
You can turn on function specs (called "instrumentation", we say that we "instrument our functions"), and run your unit tests to see if you catch any errors in this way. It's up to you when and which functions are instrumented, if you can afford it performance-wise you could instrument your functions in an actual production system and get reports of inconsistencies.
But the real benefit of adding specs to functions is property testing.
The illustration of property testing is similar to the one for spec'ing a function, but with more stuff:
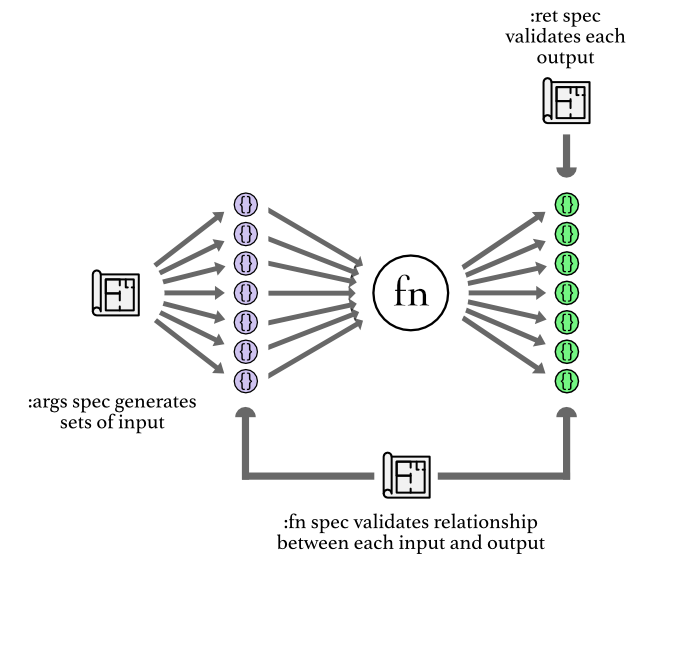
The main difference is that you use :args in order to generate multiple
examples of input that are passed to your function to produce multiple outputs
and every output is validated against the :ret spec, and also every pair of
input and output (the relationship between them) is validated against the :fn
spec.
Let's have a look at an example of property testing using specs. We'll make
our own sorting function for sorting numbers, but since this is just an
illustrative example, we'll just use sort from Clojure's core for its
implementation:
(require '[clojure.spec.alpha :as s] '[clojure.spec.test.alpha :as stest] '[clojure.pprint :as pp]) (defn num-sort [coll] (sort coll)) (s/fdef num-sort :args (s/cat :coll (s/coll-of number?)) :ret (s/coll-of number?) :fn (s/and #(= (-> % :ret) (-> % :args :coll sort)) #(= (-> % :ret count) (-> % :args :coll count)))) (pp/pprint (stest/check `num-sort))
So :args is an s/cat that contains only one thing, called :coll which is
defined as a collection of numbers and the :ret spec is also a collection of
numbers. The :fn spec is made up of two predicates: The first predicate says
that the return value should be the same as the arguments if they were sorted
using core sort (we're cheating here, but just pretend that we're testing a
new implementation). The second property says that the return value's length
should be the same as the argument's length – you can't sort something and
lose a number or gain a number.
So if you run the last expression containing the test/check it will run
num-sort multiple times with random collections of numbers with various
lengths, empty lists, nil values, covering various edge cases and it will tell
us if the function looks OK:
({:spec
#object[clojure.spec.alpha$fspec_impl$reify__9037 0x67ae26bc "clojure.spec.alpha$fspec_impl$reify__9037@67ae26bc"],
:clojure.spec.test.check/ret
{:result true, :num-tests 1000, :seed 1513253929062},
:sym bsq.vd.sony.error-reporting.reporting/num-sort})
And indeed it looks OK: :result is true, it was run 1000 times, and everything
looks OK. We've already gained something because we wouldn't have written 1000
unit tests.
In Haskell and other languages this functionality is called "QuickCheck".
So in the previous section we saw what property testing looks like for the
happy path, let's have a look at what it looks like when things go
wrong. We'll change num-sort to generally do the sorting that it was doing
before but if the collection contains the number 3, it will make a new
collection of equal length, but all the elements will be 888, so that it's
most likely the wrong result. The spec is the same as before:
(require '[clojure.spec.alpha :as s] '[clojure.spec.test.alpha :as stest] '[net.cgrand.packed-printer :as ppp]) (defn num-sort [coll] (if (seq (filter #(= % 3) coll)) (repeat (count coll) 888) (sort coll))) (s/fdef num-sort :args (s/cat :coll (s/coll-of number?)) :ret (s/coll-of number?) :fn (s/and #(= (-> % :ret) (-> % :args :coll sort)) #(= (-> % :ret count) (-> % :args :coll count))))
So we use the same spec to do a test/check, but I've massaged the result a bit
so that it becomes more readable (I have since discovered the
stest/abbrev-result function that I could have used to shorten the result and
make it more readable):
(-> (stest/check `num-sort) first :clojure.spec.test.check/ret (select-keys [:num-tests :fail :shrunk]) (update-in [:shrunk :result-data :clojure.test.check.properties/error] #(-> % ex-data (dissoc :clojure.spec.alpha/spec))) (ppp/pprint :width 60))
This will take a bit longer to run, and you get this:
{:num-tests 6, :fail [([-1 1.0625 -1 3 -3 -0.5])],
:shrunk {:total-nodes-visited 10, :depth 3, :result false,
:result-data
{:clojure.test.check.properties/error
{:clojure.spec.alpha/problems
[{:path [:fn],
:pred (clojure.core/fn [%]
(clojure.core/= (clojure.core/-> % :ret)
(clojure.core/-> % :args :coll clojure.core/sort))),
:val {:args {:coll [3]}, :ret (888)}, :via [], :in []}],
:clojure.spec.alpha/value {:args {:coll [3]}, :ret (888)},
:clojure.spec.test.alpha/args ([3]),
:clojure.spec.test.alpha/val {:args {:coll [3]}, :ret (888)},
:clojure.spec.alpha/failure :check-failed}},
:smallest [([3])]}}
Which says that stest/check ran 6 tests and that it was enough for it to find
an example of an input that provokes a bug, which is to say an example of input
that, when passed to the function, one of the defined properties is not
satisfied. This bit here:
:val {:args {:coll [3]}, :ret (888)}
…means that the minimum input that provokes the bug is the single-element
collection [3] and the result it produces is a list containing just
888. So it not only found that we have a problem, but it also zeroed-in on
the bug that we planted in the implementation.
This process of detecting the smallest possible input that provokes the bug is
called "shrinking" and it involves taking that first example of buggy input
and tries to narrow it down to find the smallest possible input that can cause
the bug. In this case the first example found to provoke the bug may have been
something like [1 6 3 8 9 10] (or any other collection containing 3), but we
managed to detect that collections with 3 are the actual culprit.
Shrinking is very useful because it makes it easier to understand the bug and the input that provokes it. Depending on your generators, the generated inputs can end up quite large: nested sequences or maps, with a lot of keys or elements etc, so you need shrinking to make it easier for you to understand what the problem is.
How does shrinking work? Let's have a look:
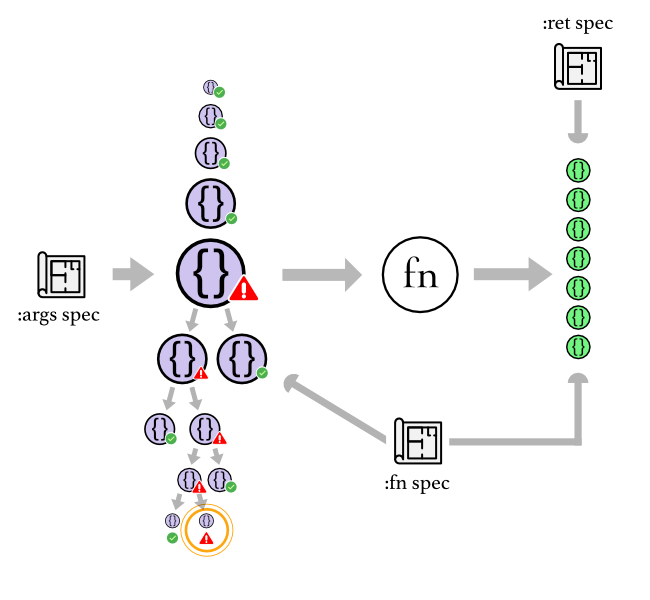
The :args spec starts generating samples of input to pass to the function, a
really small one at first, which passes the property checks (both :fn and :ret
specs), then generating slightly larger and larger inputs, of which none
provokes any bugs, and suddenly, it hits a large input that somehow provokes a
bug (in this case detected by the :fn spec).
The shrinking of this problematic input happens next. Because spec is declarative, it's possible to make a decision about how to make the input structure smaller. This depends on the type: if it's a sequence, like in our case, it will be cut in half and each half will be put through the same process: Run the function, check the specs. The half that is OK is abandoned and the half that still provokes the bug is further partitioned (if both are OK we backtrack and try to partition at a different position). This process continues recursively until we get to the smallest possible problematic input.
This is the list of use cases for spec in the official guide:
There are other interesting use cases that are emerging which we are going to explore in this second part of the article.
One alternative way to use spec is spec-provider which is a library written by me. You can pass spec-provider multiple examples data (say 15 maps) and it tries to figure out the shape of the data, what's common between them, whether something is optional or not etc, and then describe that shape as a spec.
This tool is inspired by F#'s type providers which do something similar by looking at examples of JSON or by introspecting database schemas and use the gathered information to produce F# types in order to automate the process and remove some of that burden from the developer. Spec-provider is a bit more general in the sense that the data source is always EDN – it's just Clojure data structures in memory.
Of course you can use the inferred specs as normal, for example to generate even more data:
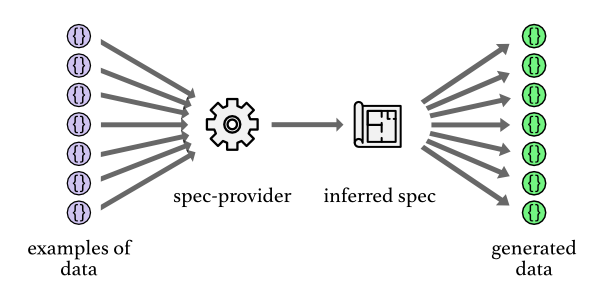
This is an example of spec-provider in action:
(require '[spec-provider.provider :as sp]) (sp/pprint-specs (sp/infer-specs [{:a 8 :b "foo" :c [:k :l]} {:a 10 :b "bar" :c ["k" "kk"]} {:a 1 :b "baz" :c ["k" "oo"] :d "boo"}] :toy/small-map) 'toy 's)
(s/def ::d string?) (s/def ::c (s/coll-of (s/or :keyword keyword? :string string?))) (s/def ::b string?) (s/def ::a integer?) (s/def ::small-map (s/keys :req-un [::a ::b ::c] :opt-un [::d]))
So if we ask spec-provider to infer a spec for these maps, we get the
::small-map spec, where it looks like :a, :b, :c are required keys (because
they appeared in all the examples of maps we passed), and :d looks like it
isn't (because it was not present in all the cases). It has also detected that
:c, is a collection of keywords or strings.
Spec-provider has some rules on how to infer specs, but they're obviously not perfect, so the idea is that you run it on your database, or files, or whatever other data you have and then you check the generated spec yourself and adjust it manually. It's essentially a development tool.
It could also be used for data inspection: The resulting spec is essentially a summary of the properties of your data. It would be possible to run spec-provider over the whole data of an ElasticSearch database (or any other mostly schemaless database) to find some anomalies you don't expect, like some key which you thought always contained a number and you may find that it sometimes is a string. Or some value that should never be nil, and you may find that in some cases it is. In fact, this is very close to how Dan Lebrero used spec-provider as described in his blog Production data never lies.
As promised, here is an example of the spec that we inferred above, generating more samples of data of the same shape:
(require '[clojure.spec.alpha :as s] '[clojure.spec.gen.alpha :as gen] '[net.cgrand.packed-printer :as ppp]) (s/def ::d string?) (s/def ::c (s/coll-of (s/or :keyword keyword? :string string?))) (s/def ::b string?) (s/def ::a integer?) (s/def ::small-map (s/keys :req-un [::a ::b ::c])) (ppp/pprint (gen/sample (s/gen ::small-map) 5))
({:a -1, :b "", :c ["" :g :g :s :+]} {:a 0, :b "", :c [:- :Q "H" "4" "w"]}
{:a 0, :b "", :c ["3G" "j" "Hj" "" :Y :D "" :_i/+ :R9/H_ :?W/* :C "9l" "" "" "Zb" ""]}
{:a 0, :b "Cdi", :c [:Q :e/n_ "" "" :l/G- :_ :n7/-f "I8C"
:Df/+f :*6/KP :q/!p :? :A/_1 "32k"]}
{:a -2, :b "88", :c [:*/?S :fX "OH" "" :b/- :YF :YI/s "4Q" "3"]})
The other pattern that has proven very useful for me and was enabled by spec is a way to access or modify deeply nested data structures (sometimes called "lenses") and having this access checked by spec. I have released this as a little library called spectacles.
So let's have a look at this spec which is a little bit more complex in that
it describes a data structure with a bit of depth. We have a top-level spec,
which has two keys, :filename and :target-dims, and we also have a value that
conforms to the spec:
(ns my-ns (:require [spectacles.lenses :as lens] [clojure.spec.alpha :as s])) (s/def ::filename string?) (s/def ::dims (s/coll-of string?)) (s/def ::target-dims (s/keys :req-un [::dims] :opt-un [::the-cat])) (s/def ::the-cat (s/cat :a string? :b number?)) (s/def ::top (s/keys :req-un [::filename ::target-dims])) (def top {:filename "foo" :target-dims {:dims ["foo" "bar"]}})
We then call lens/get with 3 parameters: the data structure, the spec that
describes it and the key to get:
(lens/get top ::top :filename)
"foo"
If you try to get a key that is not described in the spec, you get an exception:
(lens/get top ::top :WRONG)
class clojure.lang.ExceptionInfoclass clojure.lang.ExceptionInfoExceptionInfo Invalid key :WRONG for spec :my-ns/top (valid keys: #{:target-dims :filename}) clojure.core/ex-info (core.clj:4739)
Clojure's equivalent get function returns nil if you ask for a key that
doesn't exist and that may not be what you want in some cases.
Let's have a look at an example of "mutation" of the data structure with
assoc-in semantics. In this case, the first element of the vector parameter
is the spec to use, while the rest of the vector is a normal path that you
would pass to clojure.core/assoc-in:
(lens/assoc-in top [::top :target-dims :dims] 4)
class clojure.lang.ExceptionInfoclass clojure.lang.ExceptionInfoExceptionInfo Invalid value 4 for key :dims in value {:dims ["foo" "bar"]} (should conform to: (clojure.spec.alpha/coll-of clojure.core/string?)) clojure.core/ex-info (core.clj:4739)
We get an exception because the value under [:target-dims :dims] is supposed
to be a collection of strings (according to the ::top spec) but we passed a
number.
Spectacles provides spec-checked equivalents for get, get-in, assoc, assoc-in,
update, update-in, and a function to compose lenses together.
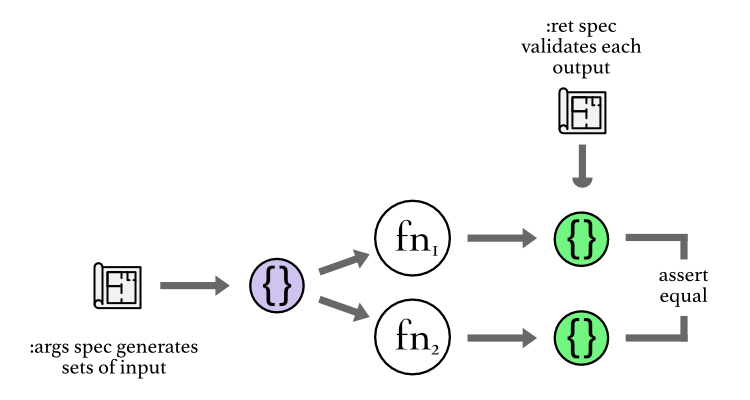
Another example of a real use case that we have encountered is when we had two functions that had to have equivalent behaviour but had different implementations. We were pretty confident about the first implementation, but not so much about the second one since it was a newer implementation and a bit more tricky.
We wanted to gain some confidence about whether the two implementations were
equivalent, so we followed this workflow: we used the same spec to generate
inputs for both functions at the same time because they both expected the same
shape of data. We then passed the generated input to both functions, validated
both outputs using a common :ret spec, and also asserted that the outputs were
equal to each other. What's interesting is that we never had to hand-code any
of the input in this process:
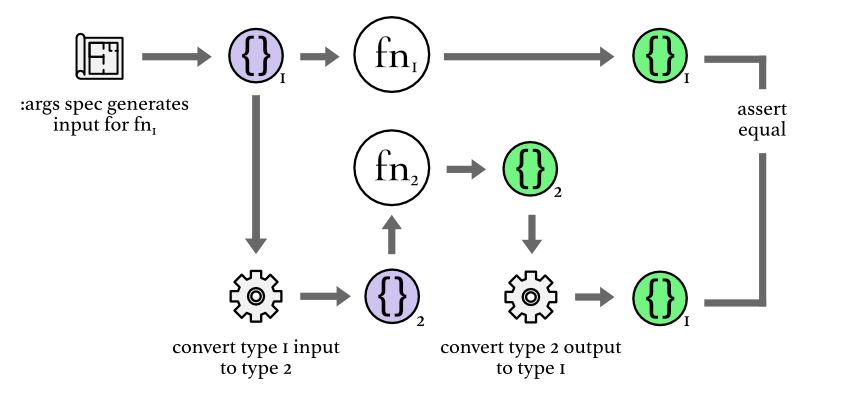
A slightly harder case was having functions that were related to each other but they didn't have exactly the same input nor output, but it made sense to compare them somehow.
More specifically, we had a function (fn2 in the diagram) that would make a calculation based on a map and returned a result. The other function (fn1) was doing the same calculation but for batches of maps: it would expect a collection of maps of the same shape as the first function, and it would return the same maps along with the result assoc'ed. The first function had a simpler implementation and we were more confident about its correctness but not so much about the second. Here's an illustration of the interfaces of both functions:
;; calculation {:foo 10 :bar 20} => fn1 => {:foo 10 :bar 20 :res 0.5} ;; batch calculation [{:foo 10 :bar 20} {:foo 11 :bar 25} {:foo 12 :bar 26} {:foo 13 :bar 27}] => fn2 => [{:foo 10 :bar 20 :res 0.5} {:foo 11 :bar 25 :res 10.9} {:foo 12 :bar 26 :res 6.9} {:foo 13 :bar 27 :res 181.9}]
In order to tackle this, we followed the following strategy: We used the :args
spec of the batch function (fn1) to create some input for it (a collection of
maps), we ran it through the function and got the output. We then got the same
generated input and broke it down programmatically to individual maps which we
then fed to fn2. We then got the output of fn2 and aggregated it again so that
it matched the shape of the batch function output. At this point we were able
to compare outputs to ensure that the functions are equivalent. This proved a
valuable test to gain some confidence that the batch function works in the
same way as the other one. It turned out that the batch function had subtle
differences the way it handled nils which would have surfaced much later as an
obscure bug in production.
Another interesting use case for spec is validating an external system which can be a library, or an external API. In our case it was an R script, so we can spec'ed a function that would invoke the R script, did property testing for it, and our test found a few bugs in the implementation. We then informed the R developers and they fixed it.
Also, Stuart Halloway uncovered a JVM bug within 10 minutes of property testing the XChart charting library.
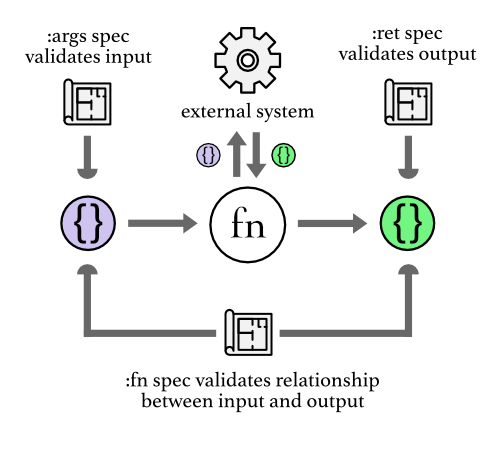
The same technique can be used to replace an external system: we could replace a legacy system with a new one, and make sure that the new system is behaving in the same way as the old one. There is a very interesting talk by Daniel Solano Gomez about such a switch. They had confidence that the old system was behaving correctly, having tested it for years. They added specs to the whole legacy API and at some point they removed the old system and replaced it with the new one (using some abstraction to hide the change) while continuing to hammer it with the same property tests as before. So the two systems were both validated against the same sets of properties and that's how they gained confidence that the new system was behaving in the same way as the old one.
Same diagram as before:
Property testing can be a very humbling experience for developers if you're trying to do anything remotely complex. For example, I was working on a tree diffing function and I wrote my unit tests, which were passing. I then tried the function in the REPL and it looked OK, but I thought it was worth doing property testing for it.
When I started running the property tests, I started seeing modes of failure
that I would never have checked for! For example, if one input contained one
nil element and the other one was empty, it would fail. And I thought "OK,
that's one thing I hadn't thought about", and I fixed it. In the next run the
same thing would happen again, I'd do another fix and think "It's surely going
to be right this time!" The same thing happened 5 or 6 times and I realised
how much out of my league I really was!
Another obvious use case of spec is documentation (and it's one of the "official" use cases). Whenever I wrote functions with complex inputs/outputs in the past I would use the docstring to describe the shape of inputs/outputs. Using spec instead makes the documentation have a more predictable and standard form for human consumption, but it's also machine-readable which means it can be used in all the other ways that we listed, so it comes with added benefits compared to string-encoded documentation.
Also, something that surprised me was that spec is a very good communication tool. At some point this non-programmer product manager was asking me about certain assumptions we had about our parameters and how they related to each other and I sent him our spec, and asked "can you read this?". He squinted a bit and said "yeah, I can sort of read this" I explained the syntax a bit and we were able to communicate effectively and it was a very nice common ground, a simple format for knowledge transmission.
What we found is that gradually, as you spec more parts of the codebase, spec slowly becomes an ontology of the data that flows through it, the inputs, the outputs and the intermediate values.
We started off with pretty naive specs that would, for example, define that a value should be a number. We would then try and use it for property testing and we would get errors that would show us that the inputs did not make sense. We would realise that it shouldn't have been described as just a number, but it had to be a positive number.
Gradually, as you try to do more property testing driven by spec, certain knowledge starts to emerge, a deeper understanding of the system, and your initial assumptions are challenged. For example some parameters have to co-exist, they both have to exist or none of them should. Or one numeric value always has to be greater than another one. Or the ranges of parameters have to be constrained. Or even more complex constraints, like if you have a large configuration, a string that's mentioned somewhere in your configuration should be also referred to somewhere else in the configuration. This last one is a bit harder to express with spec, but it's possible.
We're starting to see more science-fiction-like things with spec: Carin Meier gave a really good talk at EuroClojure in 2016 where she described how she broke code, and used spec to drive the mutation and self-healing of that code using genetic algorithms so that it again conformed to specs that she had defined. It's worth watching.
Spec is not perfect, we expect some things to be fixed in spec2, but that's still under heavy development. Some problems:
string?, Clojure knows to generate random strings. When you have some
non-standard predicates, such as an anonymous function that checks that a
number is greater than 5, Clojure can't analyze this code to make you a
generator. For complex predicates you are forced to write your own
generators so that's an extra skill you have to acquire.Apart from increasing my job satisfaction for almost a decade now, the biggest benefit I got from learning Clojure was that it challenged my way of thinking about programming and eventually taught me a new, and much more enlightened, way of thinking. I feel that working with spec has done the same thing again for me, but for a much broader subject: data.
Rich Hickey and the Clojure core team have been a huge inspiration over the years, and I'd like to thank them for their outstanding work with spec.